
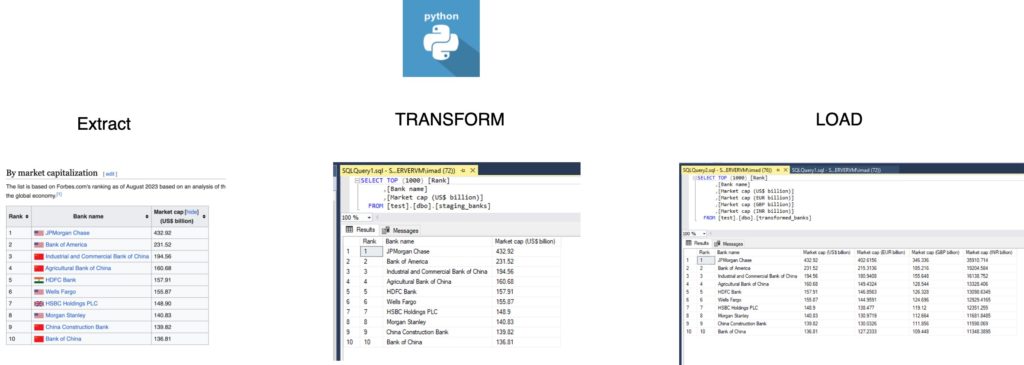
In the world of data management, the ETL (Extract, Transform, Load) process plays a crucial role in gathering, refining, and storing data for analysis. In this blog post, we’ll explore a practical example of ETL using Python to extract data from a Wikipedia source, transform it, and load it into a SQL Server database.
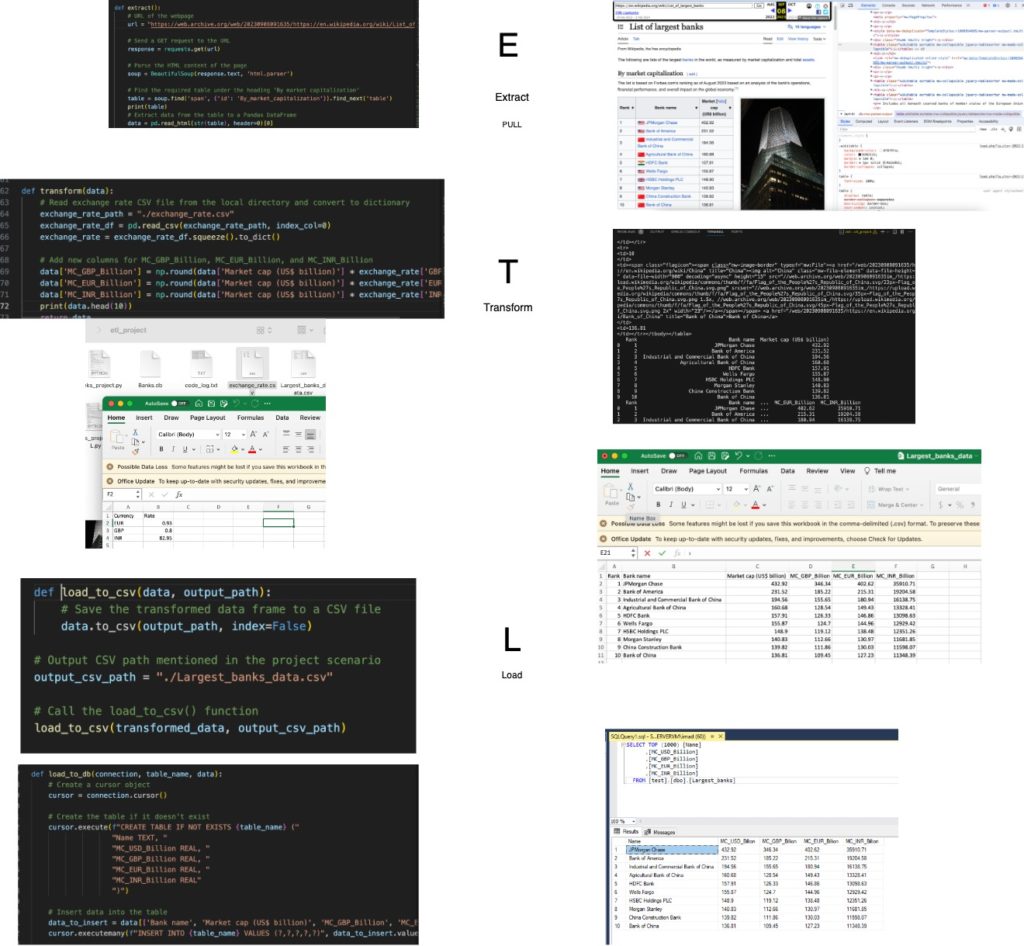
Extracting Data from Wikipedia
The first step in our ETL process involves extracting data from a Wikipedia page. We’ll be using Python along with the BeautifulSoup library to scrape the required information. The target page is a list of the largest banks, and we are particularly interested in the table under the heading ‘By market capitalization’.
# Python Code for Data Extraction
# (Note: Install required libraries if not already installed using pip install beautifulsoup4 pandas pypyodbc numpy)
import datetime
import pandas as pd
from bs4 import BeautifulSoup
import requests
import numpy as np
import pypyodbc
# Function to log progress
def log_progress(message):
timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
log_entry = f"{timestamp} : {message}\n"
with open('code_log.txt', 'a') as log_file:
log_file.write(log_entry)
# Function to extract data from Wikipedia
def extract():
url = "https://web.archive.org/web/20230908091635/https://en.wikipedia.org/wiki/List_of_largest_banks"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.find('span', {'id': 'By_market_capitalization'}).find_next('table')
data = pd.read_html(str(table), header=0)[0]
# Cleaning data: Removing last character '\n' and typecasting 'Market cap (US$ billion)' to float
data['Market cap (US$ billion)'] = data['Market cap (US$ billion)'].astype(str).str.rstrip('\n')
data['Market cap (US$ billion)'] = data['Market cap (US$ billion)'].astype(float)
return data
# Log entry
log_progress("Preliminaries complete. Initiating ETL process")
# Call the extract() function and print the returning data frame
extracted_data = extract()
print(extracted_data)This code uses the requests library to fetch the HTML content of the Wikipedia page, and BeautifulSoup is employed to parse and locate the target table. The extracted data is then converted into a Pandas DataFrame for further processing.
Transforming Data
Once the data is extracted, the next step is to transform it according to our requirements. In this example, we are introducing exchange rates to convert market capitalization values into GBP, EUR, and INR. The transformed data is then returned as a Pandas DataFrame.
# Function for data transformation
def transform(data):
exchange_rate_path = "./exchange_rate.csv"
exchange_rate_df = pd.read_csv(exchange_rate_path, index_col=0)
exchange_rate = exchange_rate_df.squeeze().to_dict()
# Adding new columns for MC_GBP_Billion, MC_EUR_Billion, and MC_INR_Billion
data['MC_GBP_Billion'] = np.round(data['Market cap (US$ billion)'] * exchange_rate['GBP'], 2)
data['MC_EUR_Billion'] = np.round(data['Market cap (US$ billion)'] * exchange_rate['EUR'], 2)
data['MC_INR_Billion'] = np.round(data['Market cap (US$ billion)'] * exchange_rate['INR'], 2)
return data
# Log entry
log_progress("Data extraction complete. Initiating Transformation process")
# Call the transform() function and print the returning data frame
transformed_data = transform(extracted_data)
print(transformed_data)
Here, we load exchange rates from a CSV file, calculate the market capitalization in GBP, EUR, and INR, and add these values as new columns to the DataFrame.
Loading Data into SQL Server
The final step is to load the transformed data into a SQL Server database. The pypyodbc library is used to establish a connection and execute SQL queries. If the table doesn’t exist, it is created, and the data is inserted row by row.
# Function to run SQL queries
def run_queries(connection, query):
cursor = connection.cursor()
cursor.execute(query)
results = cursor.fetchall()
print(f"Query statement: {query}")
print("Query output:")
for row in results:
print(row)
cursor.close()
# Function to load data into SQL Server
def load_to_sql_server(connection_string, table_name, data):
conn = pypyodbc.connect(connection_string, autocommit=True)
cursor = conn.cursor()
cursor.execute(f"SELECT COUNT(*) FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME = '{table_name}'")
table_exists = cursor.fetchone()[0]
if not table_exists:
cursor.execute(f"CREATE TABLE {table_name} ("
"Name NVARCHAR(MAX), "
"MC_USD_Billion FLOAT, "
"MC_GBP_Billion FLOAT, "
"MC_EUR_Billion FLOAT, "
"MC_INR_Billion FLOAT"
")")
for index, row in data.iterrows():
values_tuple = (row['Bank name'], row['Market cap (US$ billion)'],
row['MC_GBP_Billion'], row['MC_EUR_Billion'], row['MC_INR_Billion'])
cursor.execute(f"INSERT INTO {table_name} VALUES (?, ?, ?, ?, ?)", values_tuple)
conn.commit()
cursor.close()
# SQL Server connection string
SERVER_NAME = 'SQLSERVERVM\SQLEXPRESS'
DRIVER_NAME = 'SQL SERVER'
DATABASE_NAME = 'test'
sql_server_connection_string = f"""
DRIVER={{{DRIVER_NAME}}};
SERVER={SERVER_NAME};
DATABASE={DATABASE_NAME};
Trusted_Connection=yes;
"""
# Log entry
log_progress("Data transformation complete. Initiating Loading process")
# Call the load_to_sql_server() function
load_to_sql_server(sql_server_connection_string, "Largest_banks", transformed_data)
# Log entry
log_progress("Data loaded to SQL Server as a table. Executing queries")
# Execute queries
query_1 = "SELECT * FROM Largest_banks"
run_queries(pypyodbc.connect(sql_server_connection_string), query_1)
query_2 = "SELECT AVG(MC_GBP_Billion) FROM Largest_banks"
run_queries(pypyodbc.connect(sql_server_connection_string), query_2)
query_3 = "SELECT TOP 5 Name FROM Largest_banks"
run_queries(pypyodbc.connect(sql_server_connection_string), query_3)
# Log entry
log_progress("Process Complete")
This code establishes a connection to the SQL Server, checks for the existence of the table, creates it if needed, and inserts the data. It then executes three queries to showcase the loaded data.
By following these steps, you have successfully implemented an ETL process using Python to gather data from Wikipedia, transform it
Full code : https://github.com/syedimad1998/ETL-vs-ELT